I catch myself sometimes needing to temporarily install a package on a server (e.g. Firefox) but when I do it installs a ton of dependencies only needed for this one temporary package.
# yum install firefox ... Resolving Dependencies ... --> Finished Dependency Resolution Dependencies Resolved ... Transaction Summary ================================================================================================================================================================================ Install 1 Package (+47 Dependent packages)
So, then when I go to remove the temporary package, I now also need to remove all of the dependent packages that it just installed. That can be a pain to do manually.
Thankfully, YUM has a method to remove the package and all of it's otherwise unused dependent packages:
# yum autoremove firefox ... Resolving Dependencies ... --> Finished Dependency Resolution Dependencies Resolved ... Transaction Summary ================================================================================================================================================================================ Remove 1 Package (+47 Dependent packages)
I've been using MacPorts for several years to provide several command line packages that I also use on Linux systems. But often times when I go to use these, I encounter a couple of issues. Here's how I'm currently resolving these two issues.
I often can't find the MacPorts package in my path
My solution: Update the default PATH environmental variable on my mac.
/opt/local/bin /usr/local/bin /usr/bin /bin /opt/local/sbin /usr/sbin /sbin
The MacPorts packages currently installed are out of date
My solution: Setup a CRON for root to upgrade and clean my MacPorts install.
MAILTO=bglick@illinois.edu #------------------------------------------------- # UPDATE MAC PORTS - https://guide.macports.org/chunked/using.common-tasks.html 15 10 * * 2,5 ( /opt/local/bin/port selfupdate; /opt/local/bin/port upgrade outdated; /opt/local/bin/port uninstall inactive; /opt/local/bin/port uninstall leaves; /opt/local/bin/port uninstall obsolete ) #-------------------------------------------------
On Wednesday morning several of our CentOS 7 web servers automatically upgraded to the latest kernel, 3.10.0-229.20.1.el7.x86_64. This broke the OpenAFS client (1.6.8-1) that we use on these servers – most of our web content is hosted in AFS distributed storage.
Until we have time to debug or upgrade AFS, I decided to downgrade to the previous kernel. Here's how I did that:
## REBOOT AND BOOT INTO THE PREVIOUS VERSION OF THE KERNEL ## DISABLE ANY SCRIPTS THAT AUTOMATICALLY UPGRADE THE KERNEL ## DOWNGRADE TO THE kernel-headers PACKAGE yum downgrade kernel-headers ## REMOVE THE UPGRADED kernel AND kernel-devel PACKAGES yum remove `rpm -qa | egrep 'kernel-[0-9]+' | sort -V | tail -1` `rpm -qa | egrep 'kernel-devel-[0-9]+' | sort -V | tail -1` ## REINSTALL THE PACKAGES BROKEN BY THE KERNEL UPGRADE yum reinstall -y dkms-openafs openafs openafs-client openafs-docs openafs-krb5 reboot
I had the privilege of attending the Velocity Conference in Santa Clara, CA at the end of May. While the theme was "DevOps Web Performance", it focused primarily on DevOps and cloud computing. While neither of these were new to me, I learned a lot about the culture and benefits of both, as well as how cloud computing benefits DevOps.
DevOps
So, what is DevOps? I can't define DevOps any better than the following snippets from Wikipedia:
What is DevOps?
DevOps is a software development method that stresses communication, collaboration, integration, automation, and measurement of cooperation between software developers and other information-technology (IT) professionals.
The method acknowledges the interdependence of software development, quality assurance, and IT operations, and aims to help an organization rapidly produce software products and services and to improve operations performance. In traditional organizations there is rarely cross-departmental integration of these functions with IT operations.
DevOps promotes a set of processes and methods for thinking about communication and collaboration between development, QA, and IT operations.
DevOps Goals
Understanding the purpose of the DevOps method is more useful to me than rigidly defining it. The following are key goals that I see with DevOps:
- Faster Deployment - Allowing the developers to deploy with less effort can result in faster time to release (market), lower failure rate of releases, shortened lead time between fixes, and faster mean time to recovery of code.
- Collaboration - This is more than just better communication. Standardizing development environments that are highly collaborative aids in the software application release management for an organization. Incidents, documentation, deployments, and other events easily tracked across all teams involved. Barriers are removed between developers, QA, operations, and support roles.
- Integration - Developers find value in an integrated system for product delivery, quality testing, feature development, and maintenance releases.
- Automation - Simplifying processes allows those processes to become increasingly programmable and dynamic. This allows automation which can maximize predictability, efficiency, security, and maintainability of operational processes.
- Measurement - Without measurement you can't tell if you're actually improving the systems. Simple metrics of key processes allow for quick analysis of the process involved. Think of this as applying the scientific method to continuously measure your results.
- Empowering & Trusting Developers - Perhaps most important is the idea of granting the developers more control of the environment. The infrastructure is in place to support the applications, not the other way around.
DevOps Culture
Every organization needs to leverage it's resources to maximize their goals, typically related to money. Using a method like DevOps give an organization tools to better identify their constraints and reduce bottlenecks in processes and procedures. Again, key metrics are critical to identifying issues and measuring the improvement, ideally in realtime.
We all know to "expect the unexpected". But the key is to have methods in place that provide speed and flexibility, which allow the organization to actually deal with the unexpected. Metrics allow you to see the unexpected, while easy collaboration and deployment allows you to respond quickly. And when things do fail, we want processes to fail gracefully or even partially, then learn from that failure.
Providing good tools within an organization helps steers toward good behavior of the people and teams. Which comes first... the efficient teams, or the tools? Obviously it's an evolutionary process of improvement, but once the tools hit critical mass, the whole organization benefits and learns from them.
I notice a lot of DevOps shops make heavy use of OpenSource products. It's less of a love of the OpenSource culture, but more of an understanding that it allows for more customization and flexibility of the tools. If something doesn't quite work like needed, a DevOps team can fork or add new features to OpenSource tools. Yet at the same time, these teams realize the value in not reinventing every tool. If it works, don't waste time fixing it.
While DevOps focuses a lot on processes and tools, it loses it's value if it doesn't put the human element first. It's more about developing empathy among the team. It's not developers vs operations, or management vs engineering. It's about understanding the individuals, the teams, and the organization, then working together in trust and with power.
DevOps Tools
Below is a summary of the types of tools typically associated with DevOps, along with some specific examples of each type:
- Communication & Collaboration
- Realtime communication - chat with integrations for tickets, source control, etc.
- Documentation - wiki
- Tracking requests - tickets
- Source control
- Metrics & monitoring - make easily available to everyone
- Deployment
- Automation
- Configuration management
- Cloud & scaling
- Let the infrastructure scale and heal dynamically. I discuss this more below.
DevOps Gets Personal
Coming from scientific computing, I was one of the few attendees who wasn't at a technology company already drinking the DevOps "Kool-Aid". Over the past few years I've wavered in my desire for making use of DevOps, but this conference helped me better understand why it is much harder to implement DevOps, than to simply like it.
While utilizing various components of DevOps has tremendous value (e.g. configuration management, monitoring, source control), picking and choosing doesn't make you a DevOps shop. They key ingredient to DevOps is the empowerment and trust of the developers. It revolutionizes the work culture when the organization streamlines the process for the developers to be able control this applications.
As a system administrator on the Ops side of things, it's easy for me to (mostly inadvertently) slow down the developers. I'm not trying to make things difficult for the developers, but it comes down to three things:
- I don't always trust the developers
- I haven't prioritized setting up systems to empower the developers
- The organization doesn't always value the deployment of key tools and processes
Even if my team or organization doesn't fully endorse DevOps, there are things I can do to build my trust of my developers and to empower them to do even better work.
Cloud Computing
Virtualization and cloud computing aren't just the new hip trend. Their real benefit comes from letting the infrastructure dynamically scale and repair itself. To maintain efficiency systems should scale based upon actual current requirements (from metrics). And in the event of failures, the infrastructure should monitor itself and recover. Cloud computing provides for this dynamic infrastructure.
But, which technologies should we focus on?
Docker
Docker is very attractive for developers of multi-tiered architecture systems. Each individual application service (e.g. presentation, processing, data, etc.) are setup in individual containers. These are resources that are isolated to allow multiple independent containers to run on a single kernel instance.
Docker containers make it convenient for the developer to develop each service independently without having to spend a lot of effort focusing on the overall system. But, they also simplify the deployment process as well, because the packaged container can be copied over to other environments and easily started up there as well.
The real cloud power of Docker containers is achieved through one of the "container management" tools or frameworks. Container management tools provide functionality for bootstrapping, scheduling, discovery, configuration, proxies, application monitoring, replication, and software defined network fabrics. You can sort of think of these tools as vCenter for your containers and applications. There are currently three major frameworks for container management:
- CoreOS - uses Linux containers to manage your services at a higher level of abstraction
- systemd - container bootstrapping
- fleet - container scheduling
- etcd - service discover & shared configuration values
- flannel - overlay of software defined network fabric to communicate between containers on separate hosts
- Kubernetes - orchestration system for Docker containers
- node - runs containers and proxies service requests
- pod - represents a logical application
- scheduler - schedules pods to run on nodes
- replication controller - manages a replicated set of pods
- service - service discovery for pods
- Mesos Data Center Operating System (DCOS)
These container management tools can be used independently, or as combinations of various components of each (since they are each OpenSource projects). The Tectonic Platform is an example of a commercial product that includes the best of CoreOS Stack and Kubernetes.
These are generally implemented on top of public clouds (e.g. AWS), bare metal servers, or private clouds (e.g. OpenStack or even VMware).
Other Learnings
In addition to the core focus of the conference, I picked up some other useful stuff that is less on topic.
Linux Performance Tools
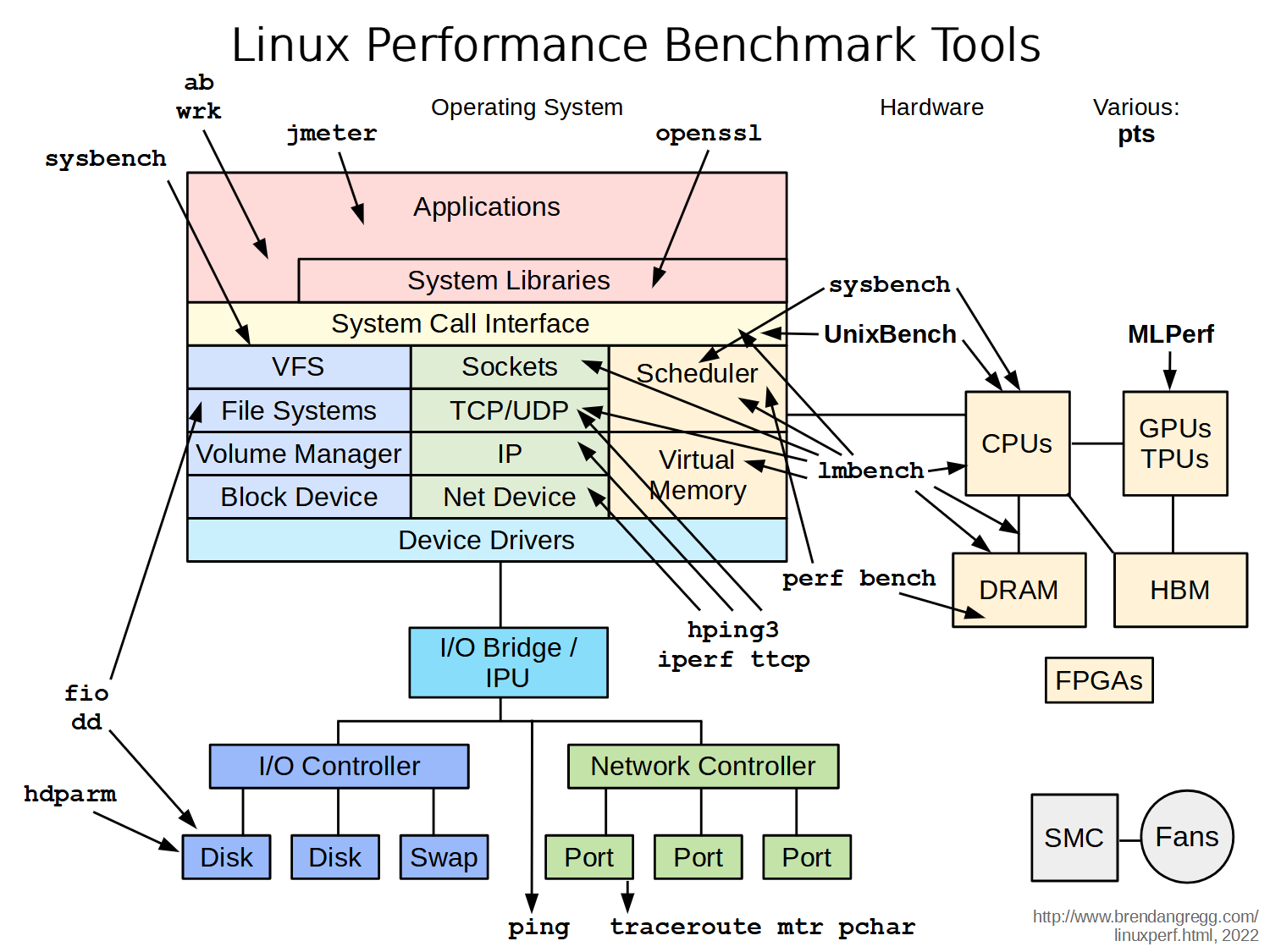
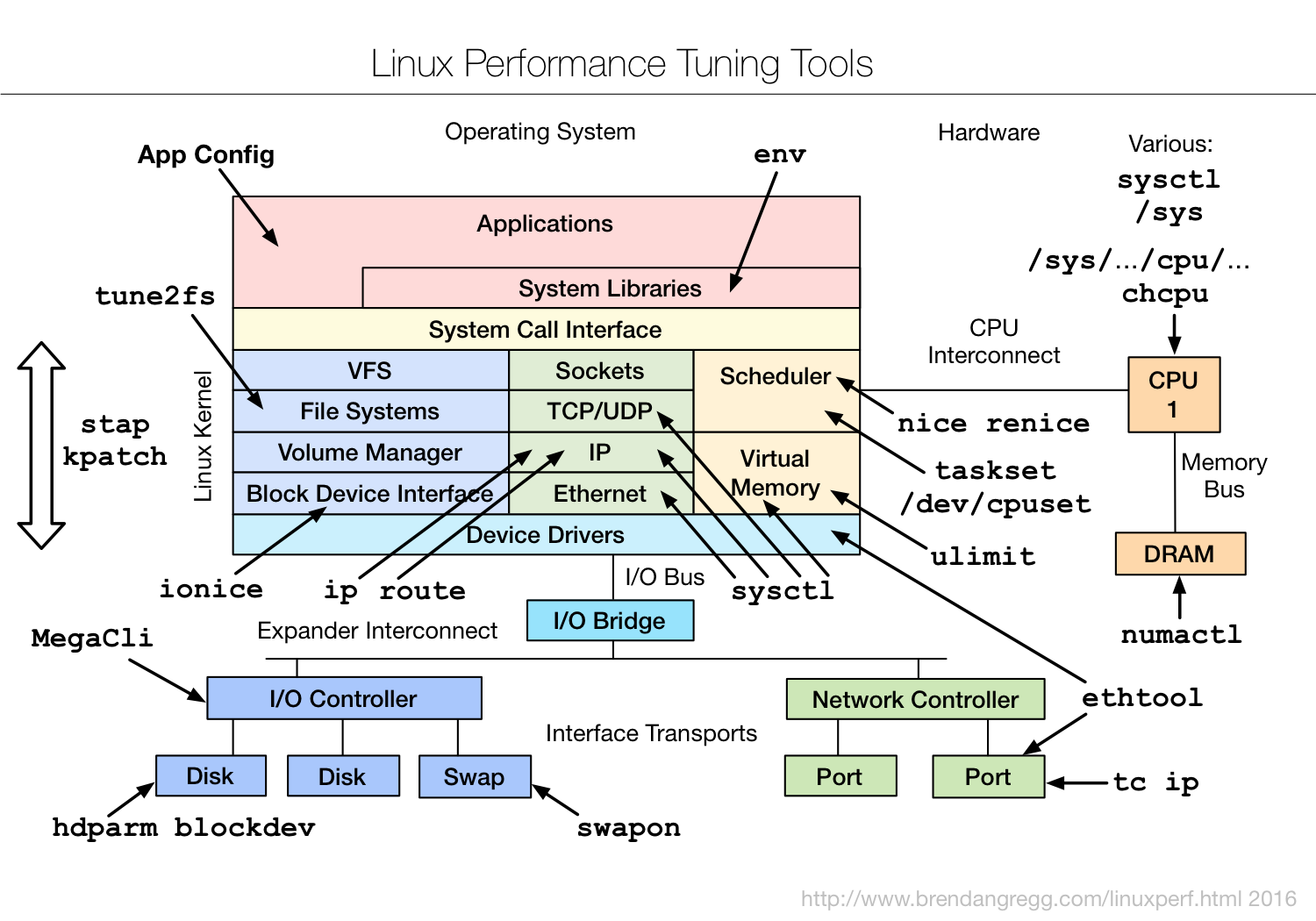
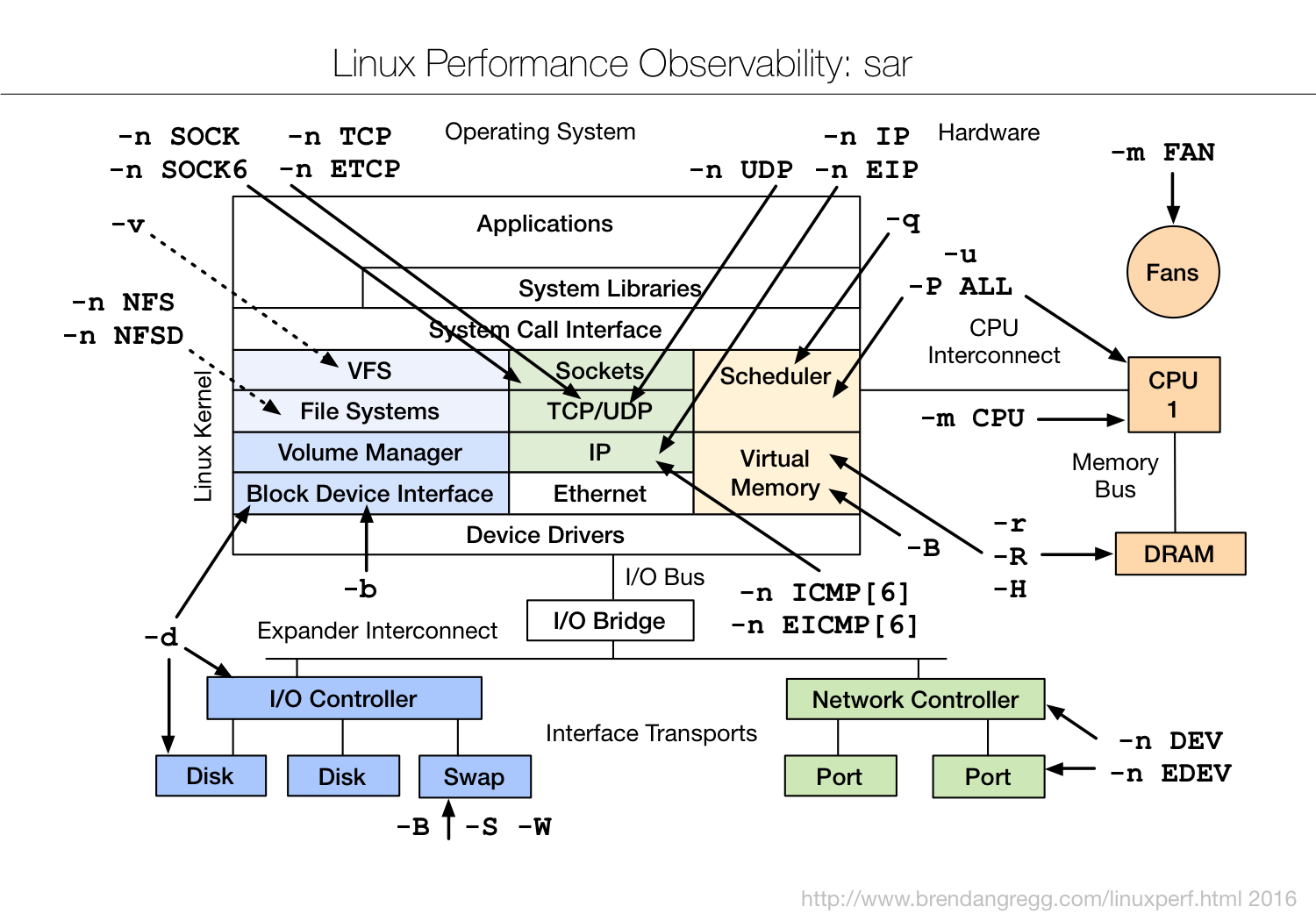
Brendan Gregg from NetFlix presented an amazing tutorial on linux performance tools. He first did a run down of how important it is to have a standard methodology for diagnosing performance issues. A standard methodology gives you a checklist of where to start and stop. Most of us tend to use anti-methods that are not methodical at all. We tend to use popular tools at random, try random stuff till the problem goes away, or blame someone else. His website details actual, useful, standardized methods that are useful. He then walked us through lots of actual tools that can be used for observability, benchmarking, tuning, states, and tracing. One useful tool he had created were block diagrams of the entire system that he then overlayed tools for various types of performance analysis (e.g. observability with sar). He has lots of this content on his website and several video presentations online.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Best Practices for MySQL HA
Colin Charles from MariaDB presented a tutorial that basically outlined the current state of options for high availability MySQL and his recommendations. His review of various options was very extensive. Here are a few of my snippets of takeaways:
- The larger your innodb_log_file_size, the longer your recovery times will be. Keep them as relatively small as possible.
- MySQL sandbox gives you easy way of installing a various MySQL server configurations via perl module.
- Generally the best redundancy is with MySQL replication with essentially no performance penalty
- The 2nd iteration of semi-synchronous replication in 5.6 - waits for 1 slave to acknowledge.
- Replication is greatly improved in 5.6 with global transaction IDs, group commits, binlog checksums, crash safe binlogs & relay logs, parallel replication, etc.
- Can create new slaves without locking tables and flushing master database.
- There are several replication monitoring tools available, e.g. Percona toolkit.
- Multithreaded slave replication is now possible.
- Tungsten replicator (open source) provides hererogenious, multi-master, and Oracle replication.
- Galera and NBD are high performance cluster solutions.
- Current frameworks for MySQL failure and load balancing:
- severalnines clusterControl provides hot backups and rolling updates.
- mysql MHA handles automated and manual failovers (replaces mysql-mmm).
- MySQL Fabric provides high availability and scaling via sharding.
- MariaDB MaxScale is a relatively new pluggable architecture for scalability, high availability, and security.
- Colin's recommendations:
- Keep with innoDB. It has lots of support and users.
- Use row based replication.
- gtid and semisync help with replication failover.
- Use multi-threaded slaves for faster performance.
Scaling Ingest
Rajiv Kurian from SignalFx gave an overview of some scaling issues they were having with metrics ingest. A lot of this was very technical, but here are a few takeaways I did have:
- L1 cache on the processor is generally 200 times faster than main memory. They optimized data structures to keep data in L1 cache.
- Measure your real application in preference over just using micro benchmarks of your system.
Off topic thought, triggered by the word "ingest"... we should consider doing workflow and data ingests via containers in a container management framework. It could be a much more resilient and dynamic infrastructure.
Vagrant & Virtualbox
Several presenters made use of Vagrant and VirtualBox. While I'd heard of this before, it was the first time I'd played with it. Vagrant provides an almost cloud-like command line interface to spin up and use VMs on your local system. It's very slick for prototyping stuff on your laptop or desktop.
Conference Resources
Conference: http://velocityconf.com/devops-web-performance-2015/
Videos: http://velocityconf.com/devops-web-performance-2015/public/content/video
Slides: http://velocityconf.com/devops-web-performance-2015/public/schedule/proceedings
When copying a lot of files with fast disk and network IO, I have often found it more efficient to copy the files as multiple threads. Copying 4-8 sets of files at the same time can better saturate IO and usually sees a 4x or more improvement in speed of the transfer.
rsync is often the easiest choice for efficiently copying over lots of files, but unfortunately it doesn't have an option for parallel threads that is built in. So, here's a rather simple way to do this using find, xargs, and rsync.
#!/bin/bash # SETUP OPTIONS export SRCDIR="/folder/path" export DESTDIR="/folder2/path" export THREADS="8" # RSYNC DIRECTORY STRUCTURE rsync -zr -f"+ */" -f"- *" $SRCDIR/ $DESTDIR/ \ # FOLLOWING MAYBE FASTER BUT NOT AS FLEXIBLE # cd $SRCDIR; find . -type d -print0 | cpio -0pdm $DESTDIR/ # FIND ALL FILES AND PASS THEM TO MULTIPLE RSYNC PROCESSES cd $SRCDIR && find . ! -type d -print0 | xargs -0 -n1 -P$THREADS -I% rsync -az % $DESTDIR/% # IF YOU WANT TO LIMIT THE IO PRIORITY, # PREPEND THE FOLLOWING TO THE rsync & cd/find COMMANDS ABOVE: # ionice -c2
The rsyncs above can be extended to work through ssh as well. When using rsync over ssh, I've found that setting the ssh encryption type to arcfour is a critical option for speed.
rsync -zr -f"+ */" -f"- *" -e 'ssh -c arcfour' $SRCDIR/ remotehost:/$DESTDIR/ \ && \ cd $SRCDIR && find . ! -type d -print0 | xargs -0 -n1 -P$THREADS -I% rsync -az -e 'ssh -c arcfour' % remotehost:/$DESTDIR/%