...
The HAL Slurm Wrapper Suite was designed to help users use the HAL system easily and efficiently. The current version is "swsuite-v0.14", which includes
srun → srun (slurm command) → swrun : request resources to run interactive jobs.
sbatch → sbatch (slurm command) → swbatch : request resource to submit a batch script to Slurm.
squeue (slurm command) → swqueue : check current running jobs and computational resource status.
| Info |
|---|
The Slurm Wrapper Suite is designed with people new to Slurm in mind and simplifies many aspects of job submission in favor of automation. For advanced use cases, the native Slurm commands are still available for use. |
Rule of Thumb
- Minimize the required input options.
- Consistent with the original "slurm" run-script format.
- Submits job to suitable partition based on the number of GPUs needed (number of nodes for CPU partition).
Usage
| Warning |
|---|
Request Only As Much As You Can Make Use OfMany applications require some amount of modification to make use of more than one GPUs for computation. Almost all programs require nontrivial optimizations to be able to run efficiently on more than one node (partitions gpux8 and larger). Monitor your usage and avoid occupying resources that you cannot make use of. |
- swrun -p <partitionswrun -q <queue_name> -c <cpu_per_gpu> -t <walltime> -r <reservation_name>
- <queue<partition_name> (required) : cpucpun1, cpun2, cpun4, cpun8, gpux1, gpux2, gpux3, gpux4, gpux8, gpux12, gpux16.
- <cpu_per_gpu> (optional) : 12 16 cpus (default), range from 12 16 cpus to 36 40 cpus.
- <walltime> (optional) : 24 4 hours (default), range from 1 hour to 72 hours24 hours in integer format.
- <reservation_name> (optional) : reservation name granted to user.
- example: swrun -q p gpux4 -c 36 40 -t 72 24 (request a full node: 1x node, x4 node4x gpus, 144x 160x cpus, 72x hours)24x hours)
- Using interactive jobs to run long-running scripts is not recommended. If you are going to walk away from your computer while your script is running, consider submitting a batch job. Unattended interactive sessions can remain idle until they run out of walltime and thus block out resources from other users. We will issue warnings when we find resource-heavy idle interactive sessions and repeated offenses may result in revocation of access rights.
- swbatch <run_script>
- <run_script> (required) : same as original slurm batch.
- <job_name> name> (requiredoptional) : job name.
- <output_file> (requiredoptional) : output file name.
- <error_file> file> (requiredoptional) : error file name.
- <queue<partition_name> (required) : cpucpun1, cpun2, cpun4, cpun8, gpux1, gpux2, gpux3, gpux4, gpux8, gpux12, gpux16.
- <cpu_per_gpu> (optional) : 12 16 cpus (default), range from 12 16 cpus to 36 40 cpus.
- <walltime> (optional) : 24 hours (default), range from 1 hour to 72 hours24 hours in integer format.
- <reservation_name> (optional) : reservation name granted to user.
example: swbatch demo.
sb
...
swb
| Code Block |
|---|
| language | bash |
|---|
| title | demo.swb |
|---|
|
#!/bin/bash
#SBATCH --job-name="demo"
#SBATCH --output="demo.%j.%N.out"
#SBATCH --error="demo.%j.%N.err"
#SBATCH --partition=gpux1
#SBATCH --time=4
srun hostname |
- swqueue
- example:
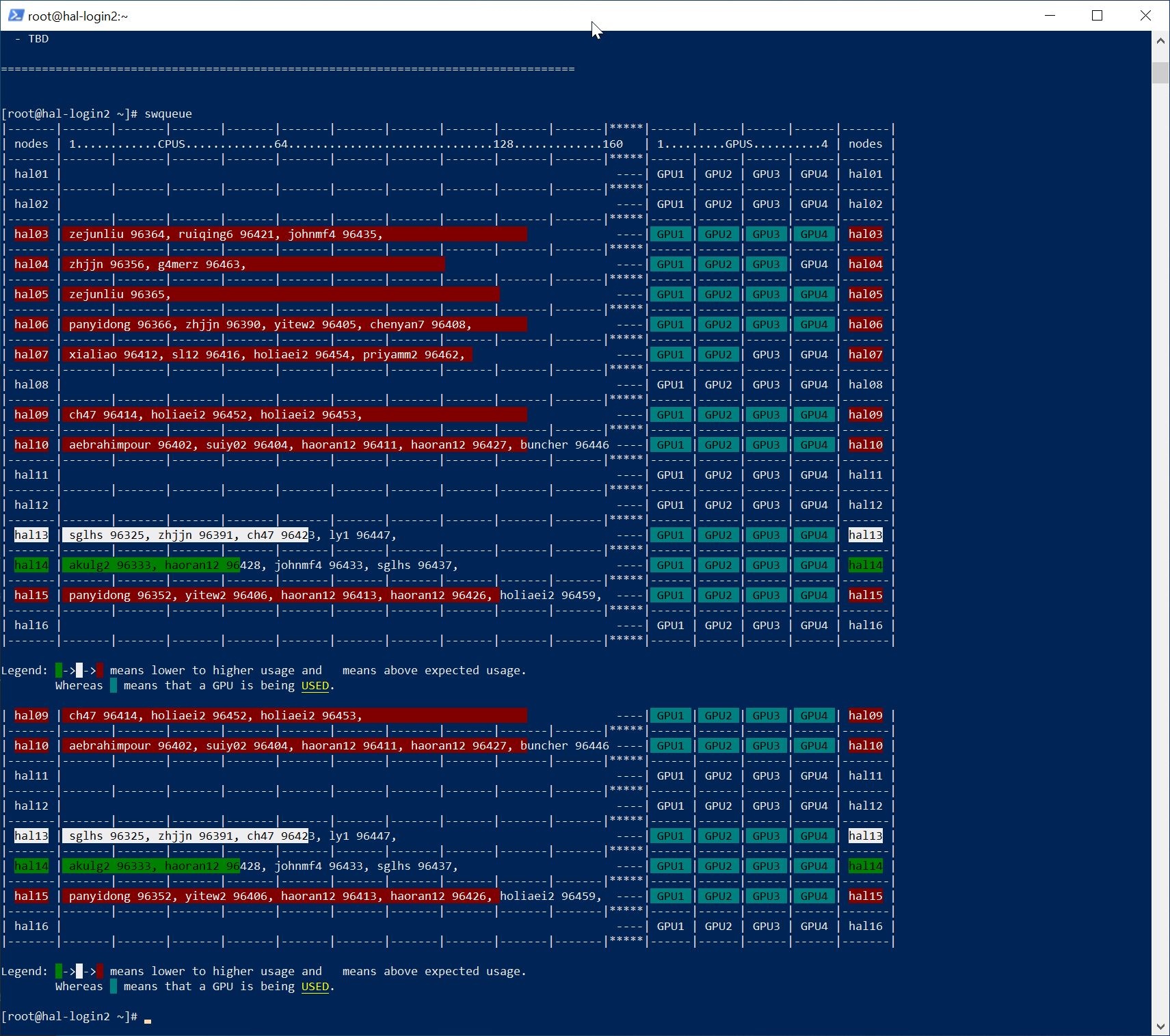 Image Added
Image Added
New Job Queues (SWSuite only)
| Info |
|---|
| title | Under currently policy, jobs requesting more than 5 nodes will require a reservation. Otherwise, they will be held by the scheduler and will not execute. |
|---|
|
|
| Partition Name | Priority | Max Walltime | Nodes
Allowed | Min-Max CPUs
Per Node Allowed | Min-Max Mem
Per Node Allowed | GPU
Allowed | Local Scratch | Description |
|---|
gpu-debughigh4 1214418144 4nonegpux1 | normal | 72 hrs | 1 | 12-36 | 18-54 GB | 1 | | designed to access 1 GPU on 1 node to run sequential and/or parallel jobs. |
| gpux2 | normal |
72 247236108 | 96 GB | 2 | none | designed to access 2 GPUs on 1 node to run sequential and/or parallel jobs. |
| gpux3 | normal |
72 3610854162 | 144 GB | 3 | none | designed to access 3 GPUs on 1 node to run sequential and/or parallel jobs. |
| gpux4 | normal |
72 4814472216 cpu | normal | 72 hrs | 1 | 96-96 | 144-144 GB | 0 | none | | designed to access 4 GPUs on 1 node to run sequential and/or parallel jobs. |
| gpux8 | normal | 24 |
gpux8 | low | 72 4814472216 | 192 GB | 8 | none | designed to access 8 GPUs on 2 nodes to run sequential and/or parallel jobs. |
| gpux12 |
low72 4814472216 | 192 GB | 12 | none | designed to access 12 GPUs on 3 nodes to run sequential and/or parallel jobs. |
| gpux16 |
low72 4814472216 Native SLURM style
Submit Interactive Job with "srun"
| Code Block |
|---|
srun --partition=debug --pty --nodes=1 \
--ntasks-per-node=12 --cores-per-socket=12 --mem-per-cpu=1500 --gres=gpu:v100:1 \
-t 01:30:00 --wait=0 \
--export=ALL /bin/bash |
Submit Batch Job
| Code Block |
|---|
sbatch [job_script] |
Check Job Status
| Code Block |
|---|
squeue # check all jobs from all users
squeue -u [user_name] # check all jobs belong to user_name |
Cancel Running Job
| Code Block |
|---|
scancel [job_id] # cancel job with [job_id] |
Job Queues
...
Max CPUs
Per Node
...
Max Memory
Per CPU (GB)
...
| designed to access 16 GPUs on 4 nodes to run sequential and/or parallel jobs. |
| cpun1 | normal | 24 hrs | 1 | 96-96 | 115.2-115.2 GB | 0 | none | designed to access 96 CPUs on 1 node to run sequential and/or parallel jobs. |
| cpun2 | normal | 24 hrs | 2 | 96-96 | 115.2-115.2 GB | 0 | none | designed to access 96 CPUs on 2 nodes to run sequential and/or parallel jobs. |
| cpun4 | normal | 24 hrs | 4 | 96-96 | 115.2-115.2 GB | 0 | none | designed to access 96 CPUs on 4 nodes to run sequential and/or parallel jobs. |
| cpun8 | normal | 24 hrs | 8 | 96-96 | 115.2-115.2 GB | 0 | none | designed to access 96 CPUs on 8 nodes to run sequential and/or parallel jobs. |
| cpun16 | normal | 24 hrs | 16 | 96-96 | 115.2-115.2 GB | 0 | none | designed to access 96 CPUs on 16 nodes to run sequential and/or parallel jobs. |
| cpu_mini | normal | 24 hrs | 1 | 8-8 | 9.6-9.6 GB | 0 | none | designed to access 8 CPUs on 1 node to run tensorboard jobs. |
HAL Wrapper Suite
...
Example Job Scripts
New users should check the example job scripts at "/opt/appssamples/samples-runscriptrunscripts" and request adequate resources.
Script
Name | Job
Type | Partition | Max | Walltime | Nodes | CPU | GPU | Memory |
(GB) | Description |
|---|
| run_ | debuggpux1_ | 00gpu16cpu_ | 96cpu_216GB24hrs.sh | interactive | debug | 4:00:00gpux1 | 24 hrs | 1 | 9616 | 0 | 1441 | 19.2 GB | submit interactive job, | 1 full 1x node for | 4 24 hours w/ 12x CPU | only 1x GPU task in " | debuggpux1" partition. |
| run_debuggpux2_01gpu32cpu_12cpu_18GB24hrs.sh | interactive | debug | gpux2 | 24 hrs4:00:00 | 1 | 1232 | 1 | 18 | submit interactive job, 25% of 1 full node for 4 hours 2 | 38.4 GB | submit interactive job, 1x node for 24 hours w/ 24x CPU 2x GPU task in " | debuggpux2" partition. |
| runsub_debuggpux1_02gpu16cpu_24cpu_36GB24hrs.shswb | interactivebatch | debug | gpux1 | 24 hrs4:00:00 | 1 | 16 | 241 | 19.2 GB | 36 | submit interactive submit batch job, | 50% of 1 full 1x node for | 4 24 hours w/ 12x CPU 1x GPU task in " | debuggpux1" partition. | run
| sub_ | debuggpux2_ | 04gpu32cpu_ | 48cpu_72GB24hrs. | shswb | interactivebatch | debug | 4:00:00gpux2 | 24 hrs | 1 | 32 | 482 | 38.4 GB | 72 | submit interactive submit batch job, | 1 full 1x node for | 4 24 hours w/ 24x CPU 2x GPU task in " | debuggpux2" partition. |
| sub_sologpux4_01node_01gpu_12cpu_18GB.sb | sbatch | solo | 64cpu_24hrs.swb | batch | gpux4 | 24 hrs72:00:00 | 1 | 1264 | 1 | 18 | submit batch job, 25% of 1 full node for 72 hours 4 | 76.8 GB | submit batch job, 1x node for 24 hours w/ 48x CPU 4x GPU task in " | sologpux4" partition. |
| sub_sologpux8_01node_02gpu_24cpu_36GB.sb | sbatch | solo | 72:00:00 | 1 | 24 | 2 | 36 | submit batch job, 50% of 1 full node for 72 hours GPU task in "solo" partition |
| sub_solo_01node_04gpu_48cpu_72GB.sb | sbatch | solo | 72:00:00 | 1 | 48 | 4 | 72 | submit batch job, 1 full node for 72 hours GPU task in "solo" partition |
| sub_ssd_01node_01gpu_12cpu_18GB.sb | sbatch | ssd | 72:00:00 | 1 | 12 | 1 | 18 | submit batch job, 25% of 1 full node for 72 hours GPU task in "ssd" partition |
| sub_batch_02node_08gpu_96cpu_144GB.sb | sbatch | batch | 72:00:00 | 2 | 96 | 8 | 144 | submit batch job, 2 full nodes for 72 hours GPU task in "batch" partition |
sub_batch_16node_64gpu_768cpu_1152GB.sb | sbatch | batch | 72:00:00 | 16 | 768 | 64 | 1152 | submit batch job, 16 full nodes for 72 hours GPU task in "batch" partition| 128cpu_24hrs.swb | batch | gpux8 | 24 hrs | 2 | 128 | 8 | 153.6 GB | submit batch job, 2x node for 24 hours w/ 96x CPU 8x GPU task in "gpux8" partition. |
| sub_gpux16_256cpu_24hrs.swb | batch | gpux16 | 24 hrs | 4 | 256 | 16 | 153.6 GB | submit batch job, 4x node for 24 hours w/ 192x CPU 16x GPU task in "gpux16" partition. |
Native SLURM style
Available Queues
| Name | Priority | Max Walltime | Max Nodes | Min/Max CPUs | Min/Max RAM | Min/Max GPUs | Description |
|---|
| cpu | normal | 24 hrs | 16 | 1-96 | 1.2GB per CPU | 0 | Designed for CPU-only jobs |
| gpu | normal | 24 hrs | 16 | 1-160 | 1.2GB per CPU | 0-64 | Designed for jobs utilizing GPUs |
| debug | high | 4 hrs | 1 | 1-160 | 1.2GB per CPU | 0-4 | Designed for single-node, short jobs. Jobs submitted to this queue receive higher priority than other jobs of the same user. |
Submit Interactive Job with "srun"
| Code Block |
|---|
srun --partition=debug --pty --nodes=1 \
--ntasks-per-node=16 --cores-per-socket=4 \
--threads-per-core=4 --sockets-per-node=1 \
--mem-per-cpu=1200 --gres=gpu:v100:1 \
--time 01:30:00 --wait=0 \
--export=ALL /bin/bash |
Submit Batch Job
| Code Block |
|---|
sbatch [job_script] |
Check Job Status
| Code Block |
|---|
squeue # check all jobs from all users
squeue -u [user_name] # check all jobs belong to user_name |
Cancel Running Job
| Code Block |
|---|
scancel [job_id] # cancel job with [job_id] |
PBS style
Some PBS commands are supported by SLURM.
...