Some local history on SIMD from 1971: https://www.ideals.illinois.edu/bitstream/handle/2142/32351/10pagedescriptio00dene.pdf?sequence=2 ( Illiac IV )
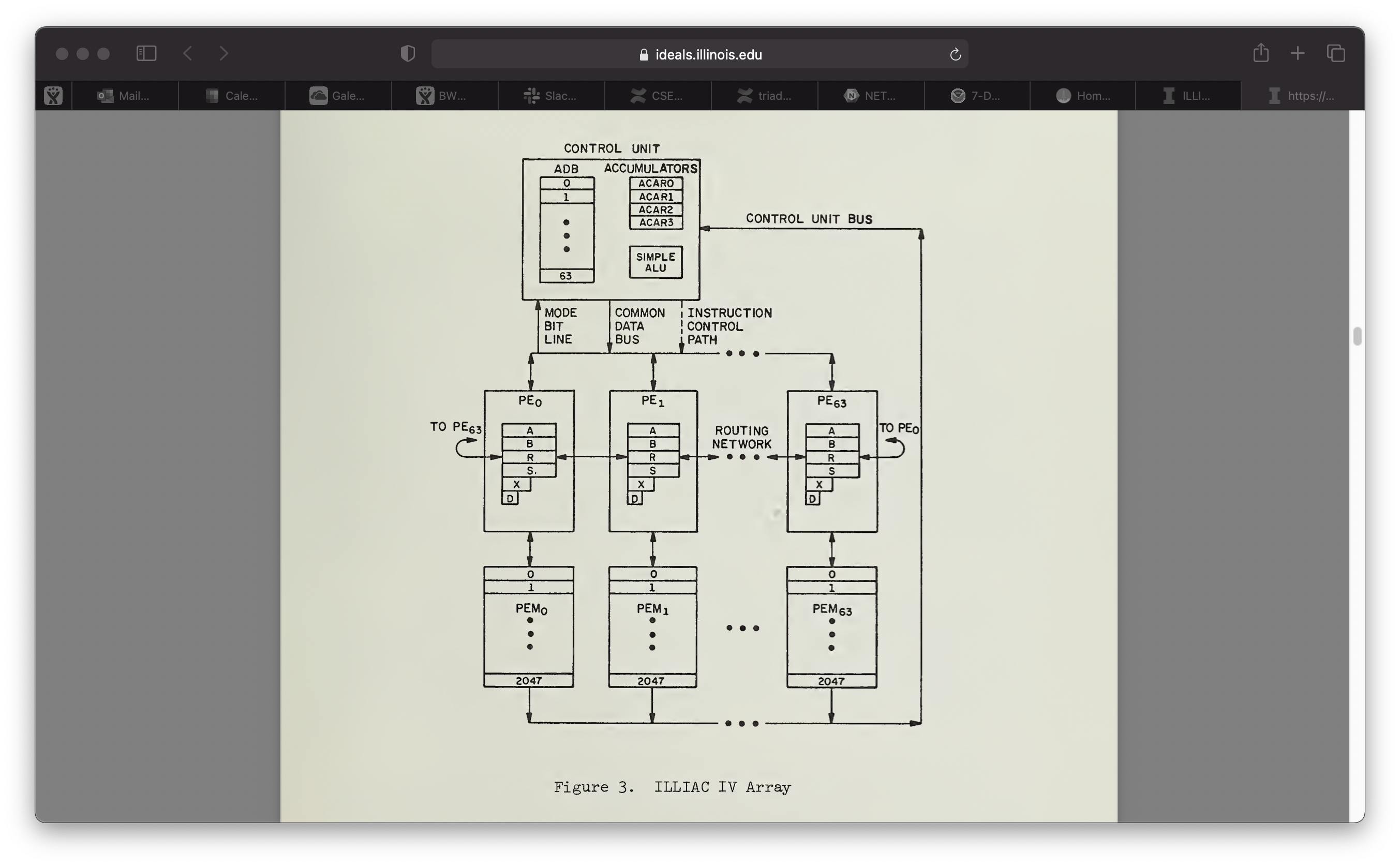
It filled a room: https://www.computerhistory.org/collections/catalog/102716109

2021: https://software.intel.com/content/www/us/en/develop/articles/introduction-to-intel-advanced-vector-extensions.html
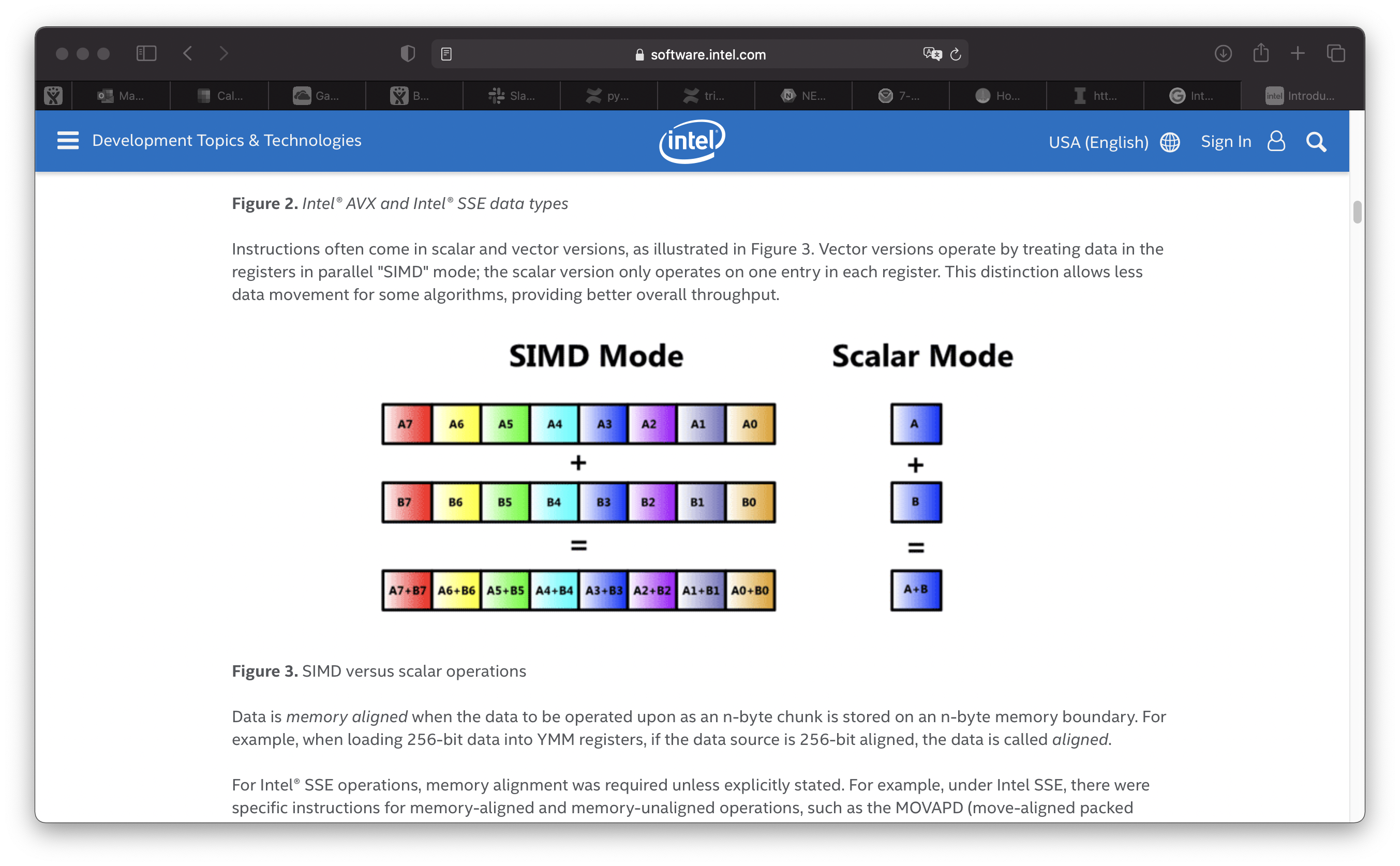
It's within most processor chips: https://www.tomshardware.com/reviews/intel-core-i7-9700k-9th-gen-cpu,5876.html

The code below has a loop that should be a perfect candidate for vectorization on most modern architectures that support SIMD instructions. Using the -qopt-report-annotate flag with the Intel compilers, notice the optimization messages in the annotated source listing.
# include <stdio.h>
# include <unistd.h>
# include <math.h>
# include <float.h>
# include <limits.h>
# include <sys/time.h>
# define STREAM_ARRAY_SIZE 29000000
# define STREAM_TYPE double
# define OFFSET 0
static STREAM_TYPE a[STREAM_ARRAY_SIZE+OFFSET],
b[STREAM_ARRAY_SIZE+OFFSET],
c[STREAM_ARRAY_SIZE+OFFSET];
void tuned_STREAM_Triad(double scalar)
{
ssize_t j;
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
a[j] = b[j]+scalar*c[j];
}
For the Intel compilers, "LOOP ... VECTORIZED" are the messages to look for with numeric code and arrays.
//
// ------- Annotated listing with optimization reports for "/mnt/a/u/staff/arnoldg/stream/triad.c" -------
//
//INLINING OPTION VALUES:
// -inline-factor: 100
// -inline-min-size: 30
// -inline-max-size: 230
// -inline-max-total-size: 2000
// -inline-max-per-routine: 10000
// -inline-max-per-compile: 500000
//
1 # include <stdio.h>
2 # include <unistd.h>
3 # include <math.h>
4 # include <float.h>
5 # include <limits.h>
6 # include <sys/time.h>
7 # define STREAM_ARRAY_SIZE 29000000
8 # define STREAM_TYPE double
9 # define OFFSET 0
10
11 static STREAM_TYPE a[STREAM_ARRAY_SIZE+OFFSET],
12 b[STREAM_ARRAY_SIZE+OFFSET],
13 c[STREAM_ARRAY_SIZE+OFFSET];
14
15 void tuned_STREAM_Triad(double scalar)
16 {
//INLINE REPORT: (tuned_STREAM_Triad(double)) [1] /mnt/a/u/staff/arnoldg/stream/triad.c(16,1)
//
///mnt/a/u/staff/arnoldg/stream/triad.c(16,1):remark #34051: REGISTER ALLOCATION : [tuned_STREAM_Triad] /mnt/a/u/staff/arnoldg/stream/triad.c:16
//
// Hardware registers
// Reserved : 2[ rsp rip]
// Available : 39[ rax rdx rcx rbx rbp rsi rdi r8-r15 mm0-mm7 zmm0-zmm15]
// Callee-save : 6[ rbx rbp r12-r15]
// Assigned : 12[ rax rdx rcx rbx rsi rdi r8-r10 zmm0-zmm2]
//
// Routine temporaries
// Total : 102
// Global : 19
// Local : 83
// Regenerable : 35
// Spilled : 1
//
// Routine stack
// Variables : 40 bytes*
// Reads : 4 [0.00e+00 ~ 0.0%]
// Writes : 6 [6.00e+00 ~ 0.0%]
// Spills : 48 bytes*
// Reads : 13 [5.69e-01 ~ 0.0%]
// Writes : 11 [1.10e+01 ~ 0.0%]
//
// Notes
//
// *Non-overlapping variables and spills may share stack space,
// so the total stack size might be less than this.
//
//
17 ssize_t j;
18 #pragma omp parallel for
//OpenMP Construct at /mnt/a/u/staff/arnoldg/stream/triad.c(18,1)
//remark #16200: OpenMP DEFINED LOOP WAS PARALLELIZED
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad.c(18,1)
//<Peeled loop for vectorization>
//LOOP END
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad.c(18,1)
// remark #15300: LOOP WAS VECTORIZED
//LOOP END
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad.c(18,1)
//<Remainder loop for vectorization>
//LOOP END
19 for (j=0; j<STREAM_ARRAY_SIZE; j++)
20 a[j] = b[j]+scalar*c[j];
21 }
22
Changing the code such that it has an array dependency ( an element of the array may be assigned the value of another element of the same array ), results in no vectorization.
18 #pragma omp parallel for
//OpenMP Construct at /mnt/a/u/staff/arnoldg/stream/triad_altered.c(18,1)
//remark #16200: OpenMP DEFINED LOOP WAS PARALLELIZED
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad_altered.c(18,1)
// remark #15344: loop was not vectorized: vector dependence prevents vectorization. First dependence is shown below. Use level 5 report for details
// remark #15346: vector dependence: assumed ANTI dependence between a[j+1] (21:22) and a[j] (22:13)
// remark #25456: Number of Array Refs Scalar Replaced In Loop: 2
//LOOP END
19 for (j=0; j<STREAM_ARRAY_SIZE; j++)
20 {
21 if (a[j] > 100) a[j] = a[j] + a[j+1];
22 a[j] = b[j]+scalar*c[j];
23 }
24 }
Trying to hide dependencies away in a function is not productive and the compiler follows the function call.
//OpenMP Construct at /mnt/a/u/staff/arnoldg/stream/triad_altered_func.c(18,1)
//remark #16200: OpenMP DEFINED LOOP WAS PARALLELIZED
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad_altered_func.c(18,1)
// remark #15344: loop was not vectorized: vector dependence prevents vectorization. First dependence is shown below. Use level 5 report for details
// remark #15346: vector dependence: assumed ANTI dependence between *x (28:3) and a[j] (22:13)
//LOOP END
19 for (j=0; j<STREAM_ARRAY_SIZE; j++)
20 {
21 myfunction(&a[j]);
22 a[j] = b[j]+scalar*c[j];
23 }
24 }
25
26 int myfunction(double *x)
27 {
//INLINE REPORT: (myfunction(double *)) [2] /mnt/a/u/staff/arnoldg/stream/triad_altered_func.c(27,1)
//
///mnt/a/u/staff/arnoldg/stream/triad_altered_func.c(27,1):remark #34051: REGISTER ALLOCATION : [myfunction] /mnt/a/u/staff/arnoldg/stream/triad_altered_func.c:27
//
// Hardware registers
// Reserved : 2[ rsp rip]
// Available : 39[ rax rdx rcx rbx rbp rsi rdi r8-r15 mm0-mm7 zmm0-zmm15]
// Callee-save : 6[ rbx rbp r12-r15]
// Assigned : 3[ rax rdi zmm0]
//
// Routine temporaries
// Total : 11
// Global : 8
// Local : 3
// Regenerable : 0
// Spilled : 0
//
// Routine stack
// Variables : 0 bytes*
// Reads : 0 [0.00e+00 ~ 0.0%]
// Writes : 0 [0.00e+00 ~ 0.0%]
// Spills : 0 bytes*
// Reads : 0 [0.00e+00 ~ 0.0%]
// Writes : 0 [0.00e+00 ~ 0.0%]
//
// Notes
//
// *Non-overlapping variables and spills may share stack space,
// so the total stack size might be less than this.
//
//
28 *x= *x-1;
29 if (*x > 10) *x = *(x+1);
30 }
Using pointers is a simple method to confuse compilers in the vectorization pass.
//OpenMP Construct at /mnt/a/u/staff/arnoldg/stream/triad_confusion.c(21,1)
//remark #16200: OpenMP DEFINED LOOP WAS PARALLELIZED
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad_confusion.c(21,1)
// remark #25084: Preprocess Loopnests: Moving Out Store [ /mnt/a/u/staff/arnoldg/stream/triad_confusion.c(24,6) ]
// remark #25084: Preprocess Loopnests: Moving Out Store [ /mnt/a/u/staff/arnoldg/stream/triad_confusion.c(25,6) ]
// remark #15344: loop was not vectorized: vector dependence prevents vectorization. First dependence is shown below. Use level 5 report for details
// remark #15346: vector dependence: assumed ANTI dependence between mya (25:6) and mya (27:14)
// remark #25439: unrolled with remainder by 2
//LOOP END
//
//LOOP BEGIN at /mnt/a/u/staff/arnoldg/stream/triad_confusion.c(21,1)
//<Remainder>
//LOOP END
22 for (j=0; j<STREAM_ARRAY_SIZE; j++)
23 {
24 mya= &a[j];
25 temp= *mya;
26 *mya= temp;
27 *mya = b[j]+scalar*c[j];
28 }
29 }
Optimization on current HPC architectures (ARM and Intel).
gcc-10 (from https://brew.sh ) Apple M1 and triad.c
galen@MacBook-galen-m1 c % gcc-10 -O3 -S -fopt-info triad.c triad.c:19:9: optimized: loop vectorized using 16 byte vectors galen@MacBook-galen-m1 c % grep v2.2d triad.s dup v2.2d, v0.d[0] fmla v0.2d, v2.2d, v1.2d
gcc-7.5.0 from Nvidia Nano SBC (Arm Cortex-A57)
galen@nano:~/c$ gcc -fopt-info -O3 -S triad.c triad.c:19:9: note: loop vectorized triad.c:19:9: note: loop turned into non-loop; it never loops triad.c:15:6: note: loop turned into non-loop; it never loops galen@nano:~/c$ grep v3.2d triad.s dup v3.2d, v0.d[0] fmla v1.2d, v2.2d, v3.2d
https://developer.arm.com/documentation/dui0801/g/A64-SIMD-Vector-Instructions/DUP--vector--general-
gcc-9.3 from Linux Mint and recycled Sony 2012 corei7
galen@galen-SVE14A27CXH:~/c$ gcc -O3 -S -fopt-info triad.c triad.c:19:9: optimized: loop vectorized using 16 byte vectors galen@galen-SVE14A27CXH:~/c$ grep xmm triad.s unpcklpd %xmm0, %xmm0 movapd (%rcx,%rax), %xmm1 mulpd %xmm0, %xmm1 addpd (%rdx,%rax), %xmm1 movaps %xmm1, (%rsi,%rax)
gcc-10.2.1 from WSL 2019 HP Pavilion corei5
galen@HP-Pavilion:~/c$ gcc -O3 -S -fopt-info triad.c
triad.c:19:9: optimized: loop vectorized using 16 byte vectors
galen@HP-Pavilion:~/c$ grep xmm triad.s
movapd %xmm0, %xmm1
unpcklpd %xmm1, %xmm1
movapd (%rcx,%rax), %xmm0
mulpd %xmm1, %xmm0
addpd (%rdx,%rax), %xmm0
movaps %xmm0, (%rsi,%rax)