NCSA wiki will be offline Friday, Apr 19, 2024, from 1700 hours until Sun, Apr 21, 2024 in order to upgrade Confluence.
...
Training Time: The following figure shows time to solution during training. The number of GPUs ranges from 2 GPUs to 64 GPUs. ImageNet training with ResNet-50 using 2 GPUs takes 20.00 hrs, 36.00 mins, 51.11 secs. With 64 GPUs across 16 compute nodes, we can train ResNet-50 in 1.00 hr, 7.00 mins, 51.31 secs, while maintaining the same level of top1 and top5 accuracy.

Training Throughput: Figure~\ref{fig:training_throughput} shows the scalability of training global througput (images/sec) with respect to the number of GPUs. We are able to achieve near linear scaling in training throughput. Note that training from 2 GPUs to 4 GPUs is within node scaling, while the training from 4 GPUs to 64 GPUs is across node scaling.

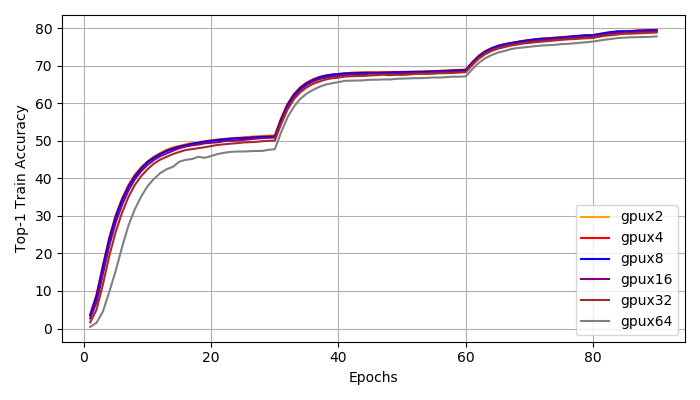
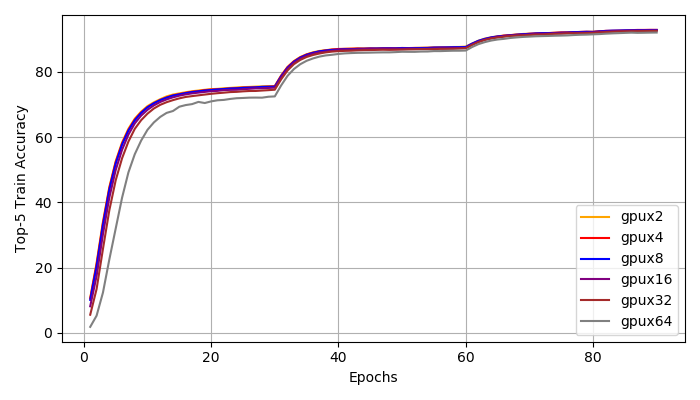
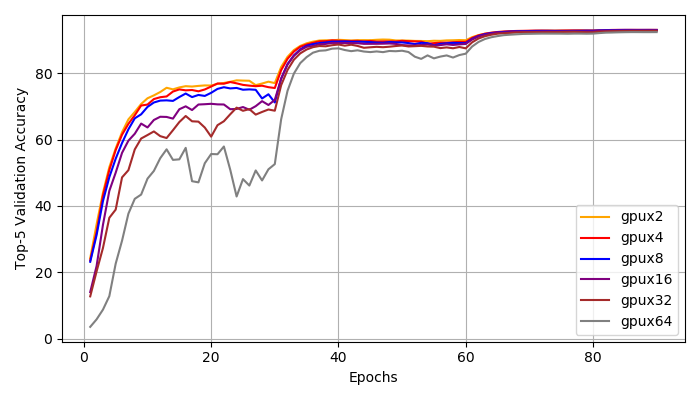
Top1, Top5 Accuracy}. We : We achieve distributed training speed-up without the loss of accuracy. All experiments reached a top1 accuracy of 76\% and a top5 accuracy of 93\%. According to Figure~\ref{fig:top1_train}, \ref{fig:top1_val}, \ref{fig:top5_train}, \ref{fig:top5_val}, all experiments have very similar learning curve. We do notice that with larger global batch size, the training is more unstable at early stages (epoch 1-30). However, the small and large batch size training curves match closely after 30 epochs and they all reach the same accuracy at the end.

I/O Bandwidth}. Figure~\ref{fig:io_bw} shows the I/O Bandwidth (GB/s) and IOPS of our file system throughout our full system ImageNet training using 64 GPUs. Between 10th and 60th epoch, the average bandwidth is $3.30$ GB/s and the average IOPS is $36.5$K.
Software Stack
...